Back to papers21 q · 21 marks 14 q · 20 marks 6 q · 18 marks 10 q · 15 marks
9 q · 11 marks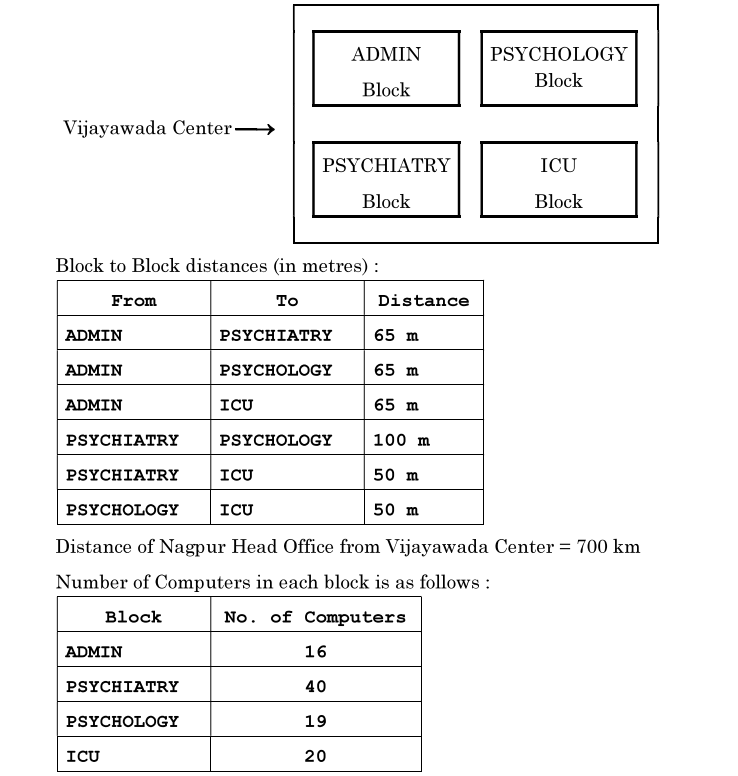
CBSE · 083Class XII
Computer Science · 2025
4 March 2025 · Main paper
Questions
37
Total marks
70
Sections
5
A
Section A
· 1-mark questionsAnswer
(c) 20
Explanation
Precedence: ** (exponent) > * (mult) > % (mod). 3**2=9. 14%9=5. 5*4=20.
Identify the correct output of the following code snippet :
python
game="Olympic2024"
print(game.index("C"))[1]
Answer
(d) ValueError
Explanation
The string contains lowercase 'c' but not uppercase 'C'. The index() method raises a ValueError if the substring is not found.
Answer
(b) Break
Explanation
Identifiers cannot be keywords. 'global', 'def', and 'with' are keywords. 'Break' is not a keyword (Python is case-sensitive, 'break' is the keyword).
Answer
(b) print("A",sep="*",10)
Explanation
In the print() function, keyword arguments like 'sep' must come after all positional arguments (values to be printed).
Consider the statements given below and then choose the correct output from the given options :
python
L=['TIC', 'TAC']
print(L[::-1])[1]
Answer
(d) ['TAC', 'TIC']
Explanation
L[::-1] creates a shallow copy of the list in reverse order. The elements themselves are not reversed.
Which of the following operator evaluates to True if the variable on either side of the operator points towards the same memory location and False otherwise ?
[1]
Answer
(a) is
Explanation
The 'is' operator checks for object identity (memory location equality), whereas '==' checks for value equality.
Consider the statements given below and then choose the correct output from the given options :
python
D={'S01':95, 'S02':96 }
for I in D :
print(I,end='#')[1]
Answer
(a) S01#S02#
Explanation
Iterating over a dictionary yields its keys. The keys are 'S01' and 'S02', printed with '#' as a separator.
While creating a table, which constraint does not allow insertion of duplicate values in the table ?
[1]
Answer
(a) UNIQUE
Explanation
The UNIQUE constraint ensures all values in a column are distinct. DISTINCT is used in SELECT queries, not as a constraint.
Consider the statements given below and then choose the correct output from the given options :
python
def Change(N) :
N=N+10
print(N,end='$$')
N=15Change(N) print(N)
[1]
Answer
(a) 25$$15
Explanation
Inside the function, N is local and becomes 25. The global N remains 15 because integers are immutable and global N wasn't referenced with 'global'.
Consider the statements given below and then choose the correct output from the given options:
python
N='5'
try:
print('WORD' + N, end='#')
except:
print('ERROR',end='#')
finally:
print('OVER')[1]
Answer
(b) WORD5#OVER
Explanation
String concatenation 'WORD' + '5' works fine ('WORD5#'). No exception is raised. The finally block always runs, printing 'OVER'.
Answer
(a) dict()
Explanation
dict() is the constructor to create a new dictionary. The others return view objects.
Answer
(a) UPDATE
Explanation
UPDATE is Data Manipulation Language. CREATE, ALTER, DROP are Data Definition Language (DDL).
Which aggregate function in SQL displays the number of values in the specified column ignoring the NULL values ?
[1]
Answer
(b) count()
Explanation
count(column) counts non-null entries. len() is Python. number/num are not SQL aggregate functions.
Answer
(c) FLOAT
Explanation
Numeric types like FLOAT, INT, etc., do not use quotes. String and Date types must be quoted.
State True or False : If table A has 6 rows and 3 columns, and table B has 5 rows and 2 columns, the Cartesian product of A and B will have 30 rows and 5 columns.
[1]
Answer
True
Explanation
Cartesian product rows = rowsA * rowsB (6*5=30). Columns = colsA + colsB (3+2=5).
Which of the following networking devices is used to regenerate and transmit the weakened signal ahead ?
[1]
Answer
(c) Repeater
Explanation
A repeater amplifies/regenerates signals to extend transmission distance.
Which of the following options is the correct protocol used for phone calls over the internet ?
[1]
Answer
(d) VoIP
Explanation
VoIP (Voice over Internet Protocol) is specifically for voice communication over IP networks.
Answer
Advanced Research Projects Agency Network
Explanation
It was the first wide-area packet-switched network and the precursor to the modern Internet.
Assertion (A): For a binary file opened using 'rb' mode, the pickle.dump() method will display an error. Reason (R): The pickle.dump() method is used to read from a binary file.
[1]
Answer
(c) A is true but R is false
Explanation
dump() writes data, so 'rb' (read binary) is the wrong mode (Assertion True). dump() is for writing, not reading (Reason False).
Assertion (A): We can retrieve records from more than one table in MYSQL. Reason (R): Foreign key is used to establish a relationship between two tables.
[1]
Answer
(b) Both A and R are true but R is not correct explanation
Explanation
Both statements are true. Joins allow retrieval from multiple tables. Foreign keys link tables. However, the ability to join isn't solely explained by the definition of a foreign key.
B
Section B
· 2-mark questionsAnswer
It exits the function and passes a value back to the caller. Example:
python
def Add(A,B): return A+B
print(Add(5,3)) # Outputs 8Explanation
The return statement terminates function execution and specifies the value to be returned to the function caller.
Write one example of each of the following in Python : (i) Syntax Error (ii) Implicit Type Conversion
[2]
Answer
(i) print(2 ; 5) # Invalid syntax (semicolon) (ii) 3 + 4.5 # Int converts to float automatically
Explanation
Syntax errors violate language grammar. Implicit conversion automatically promotes types (e.g., int to float) to prevent data loss.
Consider the following dictionaries, D and D1 :
python
D={"Suman": 40, "Raj":55, "Raman":60}
D1={"Aditi":30, "Amit":90, "Raj":20}(i) (a) Write a statement to display/return the value corresponding to the key "Raj" in the dictionary D.
[1]
Answer
python
print(D['Raj'])Explanation
Accesses the value associated with key 'Raj' using standard dictionary indexing.
Answer
python
print(len(D1))Explanation
The len() function returns the number of items (key-value pairs) in the dictionary.
(ii) (a) Write a statement to append all the key-value pairs of the dictionary D to the dictionary D1.
[1]
Answer
python
D1.update(D)Explanation
The update() method adds element(s) to the dictionary if the key is not in the dictionary. If the key is in the dictionary, it updates the key with the new value.
(ii) (b) Write a statement to delete the item with the given key "Amit" from the dictionary D1.
[1]
Answer
python
del D1['Amit']Explanation
The del keyword removes the item with the specified key. D1.pop('Amit') is also valid.
What possible output from the given options is expected to be displayed when the following code is executed ?
python
import random
Cards=["Heart","Spade","Club","Diamond"]
for i in range(2) :
print(Cards[random.randint(1,i+2)],end="#")[2]
Answer
(a) Spade#Diamond#
Explanation
In iter 1 (i=0), range is (1,2) -> index 1 or 2. In iter 2 (i=1), range is (1,3) -> index 1, 2, 3. 'Spade' is index 1. 'Diamond' is index 3. Sequence (1, 3) is valid.
The code given below accepts N as an integer argument and returns the sum of all integers from 1 to N. Observe the following code carefully and rewrite it after removing all syntax and logical errors.
python
def Sum(N)
for I in range(N):
S=S+I
return S
print(Sum(10))[2]
Answer
python
def Sum(N):
S=0
for I in range(1, N+1):
S=S+I
return S
print(Sum(10))Explanation
Added colon to def, initialized S=0, corrected range to include N (1, N+1), and indented print call.
Nisha is assigned the task of maintaining the staff data of an organization. She has to store the details of the staff in the SQL table named EMPLOYEES with attributes as EMPNO, NAME, DEPARTMENT, BASICSAL to store Employee's Identification Number, Name, Department and Basic Salary respectively. There can be two or more Employees with the same name in the organization.
(i) (a) Help Nisha to identify the attribute which should be designated as the PRIMARY KEY. Justify your answer
[1]
Answer
EMPNO. It is unique for every employee.
Explanation
Primary keys must be unique and not null. Employee Number is the standard identifier.
(i) (b) Help Nisha to identify the constraint which should be applied to the attribute NAME such that the Employees' Names cannot be left empty or NULL while entering the records but can have duplicate values.
[1]
Answer
NOT NULL
Explanation
The NOT NULL constraint enforces that a column cannot contain NULL values, but allows duplicates.
(ii) (a) Write the SQL command to change the size of the attribute BASICSAL in the table EMPLOYEES to allow the maximum value of 99999.99 to be stored in it.
[1]
Answer
ALTER TABLE EMPLOYEES MODIFY BASICSAL DECIMAL(7,2);
Explanation
ALTER TABLE MODIFY is used to change column definitions. (7,2) allows 5 digits before decimal and 2 after.
Answer
DROP TABLE EMPLOYEES;
Explanation
DROP TABLE removes the entire table structure and its data from the database.
Answer
URL (Uniform Resource Locator): It is the unique address of any resource on the Internet.
Explanation
URL specifies the location of a resource (like a web page) and the protocol used to access it.
Answer
PPP (Point to Point Protocol): This protocol is used to establish a dedicated and direct connection between two communicating devices.
Explanation
PPP is a data link layer protocol commonly used in establishing direct links between two networking nodes.
C
Section C
· 3-mark questionsWrite a Python function that displays all the lines containing the word 'vote' from a text file "Elections.txt".
[3]
Answer
python
def PrintVote():
F=open("Elections.txt")
Lines=F.readlines()
for Line in Lines:
L=Line.split()
if "vote" in L:
print(Line)
F.close()Explanation
Opens file, iterates through lines, checks if 'vote' is present as a word, prints line.
Write a Python function that displays all the words starting and ending with a vowel from a text file "Report.txt".
[3]
Answer
python
def vowels():
F=open('Report.txt')
Data=F.read()
Words=Data.split()
for Word in Words:
if Word[0] in 'aeiouAEIOU':
if Word[-1] in 'aeiouAEIOU':
print(Word,end=' ')
F.close()Explanation
Reads entire file, splits into words, checks first and last character of each word against vowel string.
Write the following user-defined functions in Python to perform the specified operations on ClrStack:
(i) push_Clr(ClrStack, new_Clr): This function takes the stack ClrStack and a new record new_Clr as arguments and pushes this new record onto the stack.
(ii) pop_Clr(ClrStack): This function pops the topmost record from the stack and returns it. If the stack is already empty, the function should display the message "Underflow".
(iii) isEmpty(ClrStack): This function checks whether the stack is empty. If the stack is empty, the function should return True, otherwise the function should return False.
[3]
Answer
python
def push_Clr(ClrStack, new_Clr):
ClrStack.append(new_Clr)
def pop_Clr(ClrStack):
if len(ClrStack) == 0:
print("Underflow")
else:
return(ClrStack.pop())
def isEmpty(ClrStack):
if len(ClrStack) == 0:
return True
else:
return FalseWrite the following user-defined functions in Python: (i) push_trail(N, myStack): Here N and myStack are lists, and myStack represents a stack. The function should push the last 5 elements from the list N onto the stack myStack.
(ii) pop_one(myStack): The function should pop an element from the stack myStack, and return this element. If the stack is empty, then the function should display the message 'Stack Underflow', and return None.
(iii) display_all(myStack): The function should display all the elements of the stack myStack, without deleting them. If the stack is empty, the function should display the message 'Empty Stack'.
[3]
Answer
python
def push_trail(N,myStack):
for i in range(-5,0,1): # Any other correct loop
myStack.append(N[i])
def pop_one(myStack):
if not myStack: #OR if myStack==[]: #OR if len(myStack)==0:
print('Stack Underflow')
else:
return myStack.pop()
def display_all(myStack):
if not myStack: #OR if myStack==[]: #OR if len(myStack)==0:
print("Empty Stack")
else:
for i in myStack[::-1]:
print(i,end=' ') Predict the output of the following code :
python
def ExamOn(mystr) :
newstr = ""
count = 0
for i in mystr:
if count%2 != 0:
newstr = newstr + str(count-1)
else:
newstr = newstr + i.lower()
count += 1
newstr = newstr + mystr[:2]
print("The new string is:", newstr)
ExamOn("GenX")[3]
Answer
The new string is: g0n2Ge
Write the output on execution of the following Python code:
python
def Change(X):
for K,V in X.items():
L1.append(K)
L2.append(V)
D={1:"ONE",2:"TWO",3:"THREE"}
L1=[]
L2=[]
Change(D)
print(L1)
print(L2)
print(D)[3]
Answer
[1, 2, 3] ['ONE', 'TWO', 'THREE'] {1: 'ONE', 2: 'TWO', 3: 'THREE'}
Explanation
Iterates dictionary items, separates keys to L1 and values to L2. Prints L1, L2, then original Dict.
D
Section D
· 4-mark questionsSuman has created a table named WORKER with a set of records to maintain the data of the construction sites, which consists of WID, WNAME, WAGE, HOURS, TYPE, and SITEID. After creating the table, she entered data in it, which is as follows:
| WID | WNAME | WAGE | HOURS | TYPE | SITEID |
|---|---|---|---|---|---|
| W01 | Ahmed J | 1500 | 200 | Unskilled | 103 |
| W11 | Naveen S | 520 | 100 | Skilled | 101 |
| W02 | Jacob B | 780 | 95 | Unskilled | 101 |
| W15 | Nihal K | 560 | 110 | Semiskilled | NULL |
| W10 | Anju S | 1200 | 130 | Skilled | 103 |
(a) Based on the data given above, answer the following questions:
(i) Write the SQL statement to display the names and wages of those workers whose wages are between 800 and 1500. (ii) Write the SQL statement to display the record of workers whose SITEID is not known (iii) Write the SQL statement to display WNAME, WAGE and HOURS of all those workers whose TYPE is 'Skilled'. (iv) Write the SQL statement to change the WAGE to 1200 of the workers where the TYPE is "Semiskilled".
[1]
Answer
(i) SELECT WNAME, WAGE FROM WORKER WHERE WAGE BETWEEN 800 AND 1500;
(ii) SELECT * FROM WORKER WHERE SITEID IS NULL;
(iii) SELECT WNAME, WAGE, HOURS FROM WORKER WHERE TYPE="Skilled";
(iv) UPDATE WORKER SET WAGE=1200 WHERE TYPE="Semiskilled";
(b) Considering the above given table WORKER, write the output on execution of the following SQL commands
(i) SELECT WNAME, WAGE*HOURS FROM WORKER WHERE SITEID = 103; (ii) SELECT COUNT(DISTINCT TYPE) FROM WORKER; (iii) SELECT MAX(WAGE), MIN(WAGE), TYPE FROM WORKER GROUP BY TYPE; (iv) SELECT WNAME, SITEID FROM WORKER WHERE TYPE="Unskilled" ORDER BY HOURS;
[1]
Answer
(i)
| WNAME | WAGE*HOURS |
|---|---|
| Ahmed J | 300000 |
| Anju S | 156000 |
(ii)
| COUNT(DISTINCT TYPE) |
|---|
| 3 |
(iii)
| MAX(WAGE) | MIN(WAGE) | TYPE |
|---|---|---|
| 1500 | 780 | Unskilled |
| 1200 | 520 | Skilled |
| 560 | 560 | Semiskilled |
(iv)
| WNAME | SITEID |
|---|---|
| Jacob B | 101 |
| Ahmed J | 103 |
A csv file "P_record.csv" contains the records of patients in a hospital. Each record of the file contains the following data: ● Name of a patient ● Disease ● Number of days patient is admitted ● Amount Write the following Python functions to perform the specified operations on this file:
(i) Write a function read_data() which reads all the data from the file and displays the details of all the 'Cancer' patients.
[2]
Answer
python
import csv
def read_data():
F=open("P_record.csv","r")
Records=list(csv.reader(F))
for R in Records :
if R[1]=="Cancer":
print(R)
F.close()Explanation
Uses csv module to read rows and checks index 1 for disease name.
(ii) Write a function count_rec() which counts and returns the number of records in the file.
[2]
Answer
python
def count_rec():
with open("P_record.csv","r") as F:
Records=list(csv.reader(F))
print(len(Records))Explanation
Reads all rows into a list and returns its length.
Assume that you are working in the IT Department of a Creative Art Gallery (CAG), which sells different forms of art creations like Paintings, Sculptures etc. The data of Art Creations and Artists are kept in tables Articles and Artists respectively. Following are few records from these two tables: Articles table:
| Code | A_Code | Article | DOC | Price |
|---|---|---|---|---|
| PL001 | A0001 | Painting | 2018-10-19 | 20000 |
| SC028 | A0004 | Sculpture | 2021-01-15 | 16000 |
| QL005 | A0003 | Quilling | 2024-04-24 | 3000 |
Artists table:
| A_Code | Name | Phone | DOB | |
|---|---|---|---|---|
| A0001 | Roy | 595923 | r@CrAG.com | 1986-10-12 |
| A0002 | Ghosh | 1122334 | ghosh@CrAG.com | 1972-02-05 |
| A0003 | Gargi | 121212 | Gargi@CrAG.com | 1996-03-22 |
| A0004 | Mustafa | 33333333 | Mf@CrAg.com | 2000-01-01 |
As an employee of CAG, you are required to write the SQL queries for the following : (i) To display all the records from the Articles table in descending order of price.
[1]
Answer
SELECT * FROM Articles ORDER BY Price DESC;
Explanation
Sorts all records by Price high to low.
Answer
SELECT * FROM Articles WHERE DOC LIKE '2020%';
Explanation
Filters by date string pattern matching year 2020.
Answer
DESC Artists;
Explanation
DESCRIBE or DESC command shows table schema.
Answer
SELECT Name FROM Articles A1, Artists A2 WHERE A1.A_code = A2.A_code AND Article='Painting';
Explanation
Joins tables on A_Code and filters by Article type.
(iv) (b) To display the name of all artists whose Article is 'Painting' through Natural Join.
[1]
Answer
SELECT Name FROM Articles NATURAL JOIN Artists WHERE Article = 'Painting';
Explanation
Natural join automatically joins on columns with same name (A_Code).
A table, named THEATRE, in CINEMA database, has the following structure:
| Fields | Type |
|---|---|
| Th_ID | char(5) |
| Name | varchar(15) |
| City | varchar(15) |
| Location | varchar(15) |
| Seats | int |
Write a function Delete_Theatre(), to input the value of Th_ID from the user and permanently delete the corresponding record from the table.
Assume the following for Python-Database connectivity: Host : localhost, User : root, Password : Ex2025
[4]
Answer
python
import pymysql as pm
def Delete_Theatre():
mydb=pm.connect(host='localhost',user='root',password='Ex2025',database='CINEMA')
MyCursor = mydb.cursor()
TID = input("Theatre ID:")
Query = "DELETE FROM Theatre WHERE Th_ID=%s"
Data=(TID,)
MyCursor.execute(Query, Data)
mydb.commit()
mydb.close()Explanation
Connects to DB, accepts ID, executes DELETE query, commits changes.
E
Section E
· 5-mark questionsA file, PASSENGERS.DAT, stores the records of passengers using the following structure: [PNR, PName, BRDSTN, DESTN, FARE], where: PNR – Passenger Number (string type) PName – Passenger Name (string type) BRDSTN – Boarding Station Name (string type) DESTN – Destination Station Name (string type) FARE – Fare amount for the journey (float type) Write user defined functions in Python for the following tasks : (i) Create() – to input data for passengers and write it in the binary file PASSENGERS.DAT.
[2]
Answer
python
import pickle
def Create():
F=open("PASSENGERS.DAT", "wb")
PNR=input("PNR No:")
PName=input("Name: ")
BRDSTN=input("Boarding at: ")
DESTN=input("Destination: ")
FARE=float(input("Fare: "))
Rec=[PNR,PName,BRDSTN,DESTN,FARE]
pickle.dump(Rec,F)
F.close()Explanation
Opens binary file in write mode, accepts inputs, dumps list object using pickle.
(ii) SearchDestn(D) - to read contents from the file PASSENGERS.DAT and display the details of those Passengers whose DESTN matches with the value of D.
[2]
Answer
python
def SearchDestn(D):
F=open("PASSENGERS.DAT", "rb")
try:
while True:
Rec=pickle.load(F)
if Rec[3]==D:
print(Rec)
except EOFError:
F.close()Explanation
Reads binary file record by record until EOF, checking index 3 for destination.
(iii) UpdateFare() - to increase the fare of all passengers by 5% and rewrite the updated records into the file PASSENGERS.DAT.
[1]
Answer
python
def UpdateFare():
try:
FR=open("PASSENGERS.DAT", "rb+")
Rec=pickle.load(FR)
for I in range(len(Rec)):
Rec[I][4]+=(Rec[I][4] * 0.05) #OR Rec[I][4]=Rec[I][4] * 1.05)
print("Updation Done!")
FR.seek(0)
pickle.dump(Rec, FR)
FR.close()
except:
print("File not found!")Explanation
Opens in read/write binary mode or uses temp file to update Fare field (index 4) by 5%.
'Swabhaav' is a big NGO working in the field of Psychological Treatment and Counselling, having its Head Office in Nagpur. It is planning to set up a center in Vijayawada. The Vijayawada Center will have four blocks –ADMIN, PSYCHIATRY, PSYCHOLOGY, and ICU. You, as a Network Expert, need to suggest the best network-related solutions for them to resolve the issues/problems mentioned in questions (i) to (v), keeping the following parameters in mind :
(i) Suggest the most appropriate location of the server inside the Vijayawada Center. Justify your choice.
[1]
Answer
PSYCHIATRY Block
Explanation
It has the maximum number of computers (40), reducing cabling cost and traffic load.
Which hardware device will you suggest to connect all the computers within each block of Vijayawada Center ?
[1]
Answer
Switch (or Hub)
Explanation
Used to connect multiple devices in a LAN segment.
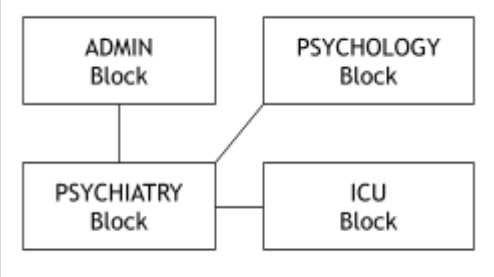
Answer
Star Topology centered at Psychiatry (ADMIN-PSYCHIATRY, PSYCHOLOGY-PSYCHIATRY, ICU-PSYCHIATRY)
Explanation
Connect Admin, Psychology, ICU directly to Psychiatry (Server Block).
Where should the router be placed to provide internet to all the computers in the Vijayawada Center ?
[1]
Answer
PSYCHIATRY Block
Explanation
The router should be placed where the server is located for central distribution.
(a) The Manager at Nagpur wants to remotely access the computer in Admin block in Vijayawada. Which protocol will be used for this?
[1]
Answer
TELNET (or SSH)
Explanation
Remote login protocols allow control of a computer from a distance.
(b) Which type of Network (PAN, LAN, MAN or WAN) will be set up among the computers connected with Vijayawada Center?
[1]
Answer
LAN
Explanation
Local Area Network covers a small geographic area like a building or campus.
End of paper
Source · CBSE Class XII Computer Science (083) · 2025